マルチモーダルAIとは、テキスト・画像・音声・動画など、複数の異なる種類のデータを統合的に処理できる人工知能のことです。1種類の情報しか扱えない従来の「シングルモーダルAI」と異なり、人間の五感に近い判断力を持ち、医療画像診断・自動運転・製造外観検査・映像×音声セキュリティなど、幅広い業界で導入が進んでいます。
2026年現在はGPT-5.5(OpenAI)、Gemini 3 Pro(Google)、Claude Opus 4.7(Anthropic)といった代表モデルが実用段階に入り、DX推進企業の技術選定・投資判断において欠かせないテーマとなっています。
➡︎【5分でわかる】ChatGPTの導入ポイントと活用事例 <資料ダウンロード>
目次
マルチモーダルAIとは
まずはマルチモーダルAIの基本概念を押さえましょう。ここでは、定義・シングルモーダルAIとの違い・近年注目される理由の3点を解説します。
マルチモーダルAIの定義
マルチモーダルAIとは、テキスト・画像・音声・動画・センサーデータなど、種類の異なる複数の情報(モダリティ)を総合的に処理できる人工知能のことです。
ここで使われる「モーダル(modal)」とは、入力情報の種類を意味します。2種類以上の情報を扱うAIを「マルチモーダルAI」、1種類の情報しか扱えないAIを「シングルモーダルAI」と呼びます。
多種類のデータを同時に処理できるため、マルチモーダルAIはインプットされる情報の量も質も充実します。その結果、シングルモーダルAIに比べて精度が高く、深い洞察や現実的な問題に対する精緻な予測を導き出せるのが特徴です。
シングルモーダルAIとの違い
シングルモーダルAIとマルチモーダルAIの違いを整理すると、次のようになります。

マルチモーダルAIが注目される理由
マルチモーダルAIが注目されている背景には、大きく3つの理由があります。
1点目は、現実世界の問題は単一のデータでは解けないケースが多いという事実です。
たとえば、医療診断では画像・数値・テキストのカルテを統合して判断する必要があり、自動運転ではカメラ・センサー・GPSなど複数のデータを同時に処理しなければ安全性を担保できません。
2点目は、ディープラーニング(深層学習)の進化です。ディープラーニングは画像・音声・自然言語といった多様なデータのパターン認識を得意としており、マルチモーダルAIの基礎技術となっています。
3点目は、GPT-5.5やGemini 3 Pro、Claude Opus 4.7など、テキスト・画像・音声・動画を統合的に扱える実用レベルのモデルが2025〜2026年に出揃ったことです。
あわせて自律的にタスクを実行する「AIエージェント」の基盤としても活用が広がり、企業の業務プロセスへの組み込みが加速しています。
★ディープラーニングについて詳しくはこちら

マルチモーダルAIの仕組みと歴史
マルチモーダルAIを支えるのはディープラーニング技術です。ここでは、内部の仕組みと、1986年の初期研究から現在の最新モデルに至るまで約40年の発展史をコンパクトに整理します。
マルチモーダルAIの仕組み
マルチモーダルAIの中核を支えるのが、ディープラーニング(深層学習)です。ディープラーニングとは、脳の神経細胞(ニューロン)の働きをモデル化したニューラルネットワークを活用する機械学習の手法で、従来デジタル化が困難だった画像・音声・自然言語などのパターン認識を得意としています。
マルチモーダルAIは、このディープラーニングを用いて各モダリティから特徴量を抽出し、それらを統合的に学習することで成立しています。
たとえば、画像からは物体や色・形状を、音声からは単語やトーン・感情を、テキストからは意味や文脈を抽出し、それらを共通の表現空間に変換して相関を学習するという仕組みです。
近年は、この統合処理を1つの大規模モデルで一気通貫に行う「ネイティブマルチモーダル」方式が主流となっています。Gemini 3 Proなどは、設計段階からテキスト・画像・音声・動画を同一アーキテクチャで処理する前提で開発されており、モダリティ間のより深い相互理解を実現しています。
マルチモーダルAI約40年の技術的発展
マルチモーダルAIの研究は、1986年頃に始まりました。当初は、音声と唇の動き(画像)を組み合わせて音声認識の精度を高める、比較的シンプルなタスクが中心でした。当時はディープラーニングがまだ実用化されておらず、研究は限定的でした。
2011年頃からディープラーニングを用いたマルチモーダル研究が本格化し、2013年にはテキストと表情画像を組み合わせてアバターに読み上げさせる「Expressive Visual Text-to-Speech」や、音声と画像から感情を認識する「Audio-Visual Emotion Recognition」などの研究が登場します。その後、画像説明文の自動生成や、テキストから画像を生成する研究(DALL·E系)へと発展していきました。
転換点となったのが、2023年のGPT-4登場です。テキスト+画像を扱える大規模言語モデルが一般ユーザーにも実用レベルで使えるようになり、2024年のGPT-4oで音声入出力がネイティブ対応。2025年のGPT-4.1、Gemini 2.5 Pro、Claude Sonnet 4を経て、2026年にはGPT-5.5、Gemini 3 Pro、Claude Opus 4.7といったより高い推論能力と高解像度マルチモーダル理解を備えたモデルが次々登場。マルチモーダルAIは研究フェーズから実用・ビジネス活用フェーズへと完全に移行しました。
➡︎【5分でわかる】ChatGPTの導入ポイントと活用事例 <資料ダウンロード>
マルチモーダルAIにできること
複数モダリティを組み合わせることで、シングルモーダルAIでは実現できなかったタスクが可能になります。ここでは代表的な3つの活用パターンを紹介します。
テキスト・画像・音声・動画の統合処理
マルチモーダルAIの代表的な機能が、複数モダリティを組み合わせた処理です。画像と質問文(テキスト)を与えて回答を生成する、手書きメモ(画像)からWebサイトのコードを出力する、動画をアップロードしてシーン内容を要約する、リアルタイム音声で対話するといったタスクが実用化されています。
逆方向の処理も可能で、テキスト指示から画像やイラストを生成する技術(Gemini Nano Banana、DALL·E系、Stable Diffusionなど)もマルチモーダルAIの一種です。
行動認識・異常検知
画像・音声・動作情報を同時処理できるマルチモーダルAIは、監視カメラや工場の異常検知にも活用されています。
たとえば、監視カメラの場合、従来の画像情報だけでは「人が集まっている」としか認識できなかった状況でも、音声情報と組み合わせることで「大声で怒鳴り合っている」と判断できます。警備室のアラームを鳴らすなどトラブル防止につながるのです。
工場の生産設備では、振動・温度・湿度などのセンサーデータに加え、画像・音声データを組み合わせることで、機械の異音・磨耗・異物混入をいち早く発見できます。生産設備のメンテナンスや作業員の安全確保、製品の品質向上に直結します。
より人間に近い判断
マルチモーダルAIは、画像・音声・センサーデータなどを同時処理するため、人間が視覚・聴覚・触覚といった五感を使って認知・判断する能力に近い動きをします。加えて、ディープラーニングによる継続学習で次の動きを予測したり、熟練技能を応用したりすることも可能です。
この特性により、タオルの折りたたみやサラダの盛り付けといった繊細な作業を行うロボット、介護施設の利用者の話し相手になるアシスタント、運転手の表情・声から状態を把握する車内見守りシステムなど、「人間的な判断」が必要な領域での応用が進んでいます。
★AI画像認識について詳しくはこちら

★自然言語処理について詳しくはこちら

代表的なマルチモーダルAIモデル【2026年版】
2025〜2026年は、マルチモーダルAIが完全に実用段階に突入した期間です。ここでは、AI技術選定を検討する担当者に向けて、2026年5月時点で利用できる代表的な3モデルを比較します。
モデル比較表
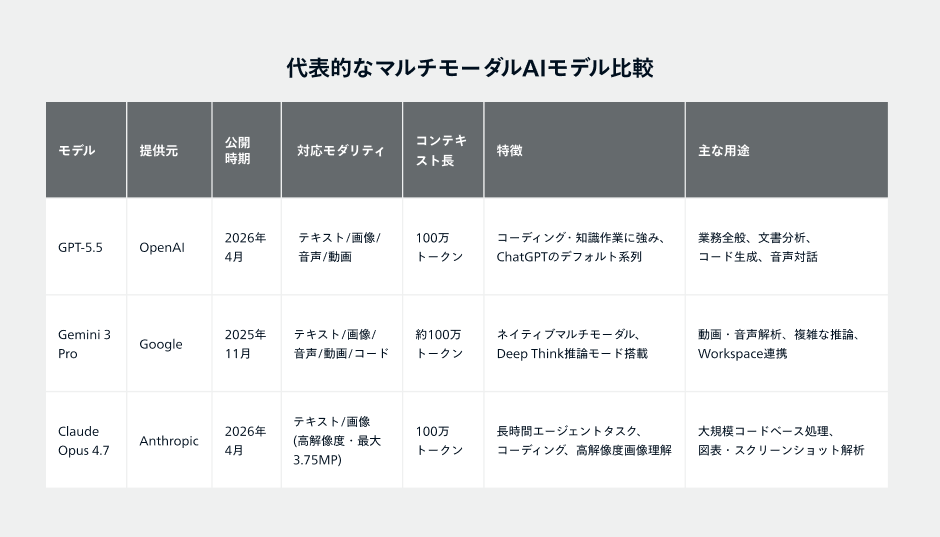
GPT-5.5(OpenAI):知識作業・コーディング・マルチモーダル推論を統合したフラッグシップ
GPT-5.5は、OpenAIが2026年4月23日にリリースしたフラッグシップモデルです。100万トークンのコンテキストウィンドウを備え、コーディング・コンピューター操作・知識作業・科学研究の4分野で前世代を大きく上回る性能を発揮します。マルチモーダル推論ベンチマーク「MMMU-Pro」のスコアも前世代比で大幅向上しており、画像・動画を含む複合的な理解力が強化されました。
2026年5月5日には、ChatGPTのデフォルトモデルとして派生版「GPT-5.5 Instant」が展開され、医療・法律・金融といった高リスク領域でのハルシネーションを大幅に削減。ビジネスユースでの実用度がさらに高まっています。
公式情報:https://openai.com/
Gemini 3 Pro(Google):テキスト・画像・音声・動画を1つのモデルで完全統合
Gemini 3 Proは、Googleが2025年11月18日にリリースしたマルチモーダル特化型モデルです。テキスト・画像・音声・動画・コードを単一アーキテクチャでネイティブ処理できる点が最大の特徴で、最大1時間規模の動画解析や、長尺音声の一括処理(会議のリアルタイム要約・感情分析など)に対応します。
「Deep Think」と呼ばれる深い推論モードを搭載し、複雑なロジックを要するタスクで論理的な自己修正を行いながら最適解を導きます。Google AI UltraプランやWorkspace連携で利用でき、Geminiアプリのデフォルトモデルにも採用されています。なお、開発者向けAPIでは後継のGemini 3.1 Proへの移行も進んでおり、最新動向の継続チェックが必要です。
公式情報:https://deepmind.google/models/gemini/
Claude Opus 4.7(Anthropic):高解像度画像・長文・コーディングに特化したフラッグシップ
Claude Opus 4.7は、Anthropicが2026年4月16日にリリースした最上位モデルです。100万トークンのコンテキスト、高解像度画像対応(最大2576px/3.75MP)、そして長時間にわたる自律的なエージェントタスクの遂行能力が大きな特徴。スクリーンショット読解、複雑な図表からのデータ抽出、ピクセル単位の整合性が必要な作業で高い精度を発揮します。
入力モダリティはテキストと画像で、音声・動画には対応していません。そのため純粋なマルチモーダル幅では他2モデルに譲りますが、長大なコードベース分析・ドキュメント処理・コーディング業務の自動化では業界トップクラスの評価を受けています。
公式情報:https://www.anthropic.com/claude
★ChatGPTの基本について詳しくはこちら

【業界別】マルチモーダルAIの活用事例【2026年版】
マルチモーダルAIは、2025〜2026年にかけて多くの業界で実用段階に達しました。ここでは、マルチモーダルAI特有の価値(複数モダリティの統合処理)が発揮されている業界事例を、1次ソースに基づいて紹介します。
医療(診断支援・遠隔医療・医療画像解析)
医療分野では、画像・数値・テキストといった複数種類のデータを統合処理できるマルチモーダルAIの特性が大きな武器となっています。
富士フイルムは2025年3月、CT・MRIの読影レポートをマルチモーダルAIで構造化する技術を発表しました。医療画像と自然言語のレポートを組み合わせて処理することで、構造化精度90%以上を達成しています。医師の読影業務の効率化と、電子カルテとの連携強化が期待されています。
参考:富士フイルム 読影レポート構造化AI(2025年3月)
製造業(産業用ロボット・品質外観検査)
製造現場では、画像・センサーデータ・音声を組み合わせた異常検知や外観検査が急速に普及しています。
オムロンは、シート製品の欠陥検知において、複数の検査モダリティを組み合わせることで見逃し率0.00%を達成したと報告しています。画像データだけでは検出が難しかった微細な欠陥も、マルチモーダル処理によって高精度に判別できるようになりました。
小売業(商品推薦・非定型データ分析)
小売業では、画像・購買履歴・テキスト情報を統合したパーソナライズドレコメンドが実装段階に入っています。
楽天グループは2025年11月、画像・購買履歴・テキストを統合処理するマルチモーダル推薦エンジンを発表しました。約5億点に及ぶ商品データから、ユーザー一人ひとりに最適化された商品推薦を実現しています。
参考:楽天グループ マルチモーダル推薦システム(2025年11月)
自動車(自動運転・ドライバー安全支援)
自動運転はマルチモーダルAIの代表的な応用領域です。複数のカメラ・マイク・ミリ波センサー・GPS・LiDARなど多様なセンサーから得られる情報を統合処理し、人間の五感に近い認知・判断を行います。
日産自動車は2025年9月、カメラ11台・レーダー5基・LiDAR 1基を組み合わせたマルチモーダルセンシングによる自動運転車両の東京都内公道実証を発表。2027年度の量産化を目指しています。
セキュリティ(監視カメラ×音声分析の組み合わせ)
セキュリティ分野では、映像と音声を組み合わせたマルチモーダル認証・監視が主流となりつつあります。
NECは2026年3月、同社の顔認証技術がNIST(米国国立標準技術研究所)評価でエラー率0.06%・世界第1位を獲得したと発表しました。映像データと他のモダリティを組み合わせることで、より高精度な本人確認とセキュリティ監視を実現しています。
マルチモーダルAIの課題と対策
高精度・多機能なマルチモーダルAIですが、導入にあたってはいくつかの課題があります。主要な3つを押さえておきましょう。
データ処理の計算負荷・コスト
マルチモーダルAIは複数モダリティを同時処理するため、シングルモーダルAIと比較して計算資源(GPU・メモリ)の消費が大きく、APIコールあたりのコストも高くなります。とくに動画解析や長尺音声の処理では、レスポンス時間とコストの両面で負担が増加します。
対策としては、用途に応じたモデルの使い分け(GPT-5.5 mini、Gemini 3 Flash、Claude Haiku 4.5などの軽量モデル活用)、不要なモダリティを省いたプロンプト設計、キャッシュや前処理の工夫によるAPI呼び出し回数の削減などが有効です。
プライバシー・セキュリティリスク
マルチモーダルAIでは、顔画像・音声・会話テキストなど個人識別に直結するデータを扱う場面が多く、プライバシー保護とセキュリティ対策が従来以上に重要になります。医療分野の診断画像や、監視カメラ映像の扱いは特に慎重な設計が求められます。
対策としては、オンプレミスまたはプライベートクラウド環境での運用、データの匿名化・マスキング処理、アクセス権限の厳格な管理、各国・各業界の規制(個人情報保護法、医療情報ガイドライン等)への準拠が挙げられます。
説明責任(ブラックボックス問題)
マルチモーダルAIはディープラーニングベースのため、なぜその判断に至ったかを説明しづらい「ブラックボックス問題」を抱えています。医療診断や自動運転、金融審査など、判断の根拠が問われる領域では特に課題となります。
対策としては、説明可能AI(XAI)技術の活用、判断根拠となったモダリティや特徴量の可視化、最終判断に人間を介在させる「Human-in-the-Loop」運用設計などが有効です。
マルチモーダルAIの今後の展望【2026年版】
マルチモーダルAI市場は、急速な拡大期に入っています。調査機関の予測には幅がありますが、複数の調査会社が2025〜2034年にかけて年平均30%超のCAGRで成長すると予測しており、2030年代半ばには市場規模が現在の十数倍に達するシナリオも示されています。
テキスト・画像・音声を統合処理するこの技術領域の急成長は、AI-OCRを含むドキュメントAI分野への投資判断においても重要な文脈となります。
★OCRについて詳しくはこちら

医療診断AIの高度化
医療分野では、画像・ゲノムデータ・電子カルテ・ウェアラブルデバイスからのリアルタイム情報を統合するマルチモーダル診断AIが、今後さらに高度化していく見込みです。精密医療・遠隔医療・予防医療の領域で、熟練医師と同等以上の診断精度を実現することが期待されています。
自律型AIエージェントへの発展
マルチモーダルAIは、単なる認識・生成にとどまらず、自律的にタスクを計画・実行するAIエージェントの基盤技術として発展しています。2026年に入ってからは、Claude Opus 4.7のような長時間自律タスクに耐えるモデルや、OpenAIのGPT-Realtime系のような連続音声対話モデルが登場し、画面操作や音声・映像を統合して判断する業務自動化エージェントが本格的な実用フェーズに入りました。
空間コンピューティング・XRとの融合
Meta・Apple・Googleが注力するXR(VR/AR/MR)や空間コンピューティングの領域でも、マルチモーダルAIの役割が拡大しています。ARグラスを装着したユーザーの視覚・音声・位置情報・行動履歴を統合処理し、その場の文脈に応じたアシストを提供するデジタルアシスタントが、近い将来実用化される見込みです。
まとめ
マルチモーダルAIは、テキスト・画像・音声・動画など複数のデータを統合処理し、人間の五感に近い判断を可能にする人工知能です。
2026年現在、GPT-5.5、Gemini 3 Pro、Claude Opus 4.7といった代表モデルが実用段階に達し、医療・製造・小売・自動車・セキュリティなど幅広い業界で成果を上げています。
計算コストやプライバシー、説明責任といった課題はあるものの、市場は年平均30%超の高成長が予測され、今後はAIエージェントやXRとの融合によってさらに応用範囲を広げていきます。
自社でマルチモーダルAIをどう活用するか、戦略的な検討を始める好機といえるでしょう。
➡︎【5分でわかる】ChatGPTの導入ポイントと活用事例 <資料ダウンロード>
よくある質問(FAQ)
Q1. マルチモーダルAIとは?
A. テキスト・画像・音声・動画など、複数の異なる種類のデータを統合的に処理できる人工知能のことです。1種類のデータしか扱えないシングルモーダルAIと対比される概念で、人間の五感に近い総合的な判断を可能にします。
Q2. シングルモーダルAIとの違いは?
A. 最大の違いは「扱えるデータの種類の数」です。シングルモーダルAIは画像のみ・テキストのみなど1種類のデータに特化しているのに対し、マルチモーダルAIは複数種類を同時に処理できます。結果として、マルチモーダルAIの方が精度が高く、複雑な現実世界の問題に対応しやすくなります。
Q3. 代表的なモデルは?
A. 2026年5月時点の代表モデルは、OpenAIの「GPT-5.5」、Googleの「Gemini 3 Pro」、Anthropicの「Claude Opus 4.7」の3つです。テキスト・画像・音声・動画などの対応範囲や、コンテキスト長、得意領域に違いがあります。AIモデルは進化が速いため、選定時は最新の公式情報を確認することをおすすめします。
Q4. 業界別の活用事例は?
A. 医療分野では読影レポートの構造化AI、製造業では品質外観検査、小売業ではパーソナライズドレコメンド、自動車では自動運転、セキュリティでは顔認証など、マルチモーダル特有の強みを活かした導入が進んでいます。
Q5. 導入時の課題は?
A. 主な課題は「計算負荷・コスト」「プライバシー・セキュリティリスク」「説明責任(ブラックボックス問題)」の3つです。軽量モデルの活用、オンプレミス運用、説明可能AI(XAI)の導入などで対処していきます。
➡︎【5分でわかる】ChatGPTの導入ポイントと活用事例 <資料ダウンロード>
サービス・プロダクト開発を検討している企業ご担当者様へ
モンスターラボは、約20年にわたるサービス・プロダクト開発実績から得られたデジタル領域の知見や技術力を活かし、デジタルプロダクト開発事業を展開しています。
先端テクノロジーに対応した高度なIT人材があらゆるプラットフォーム上での開発を支援します。アジャイル開発とDevOpsによる柔軟な開発進行や、国内外のリソースを活用したスケーラブルな開発体制の構築も可能です。 また、リリース後の保守運用や品質向上支援まで伴走可能です。
モンスターラボが提供するサポートの詳しい概要は以下リンクをご確認ください。
直近のイベント



記事の作成者・監修者

平田 大祐(株式会社モンスターラボ 常務執行役員)
2004年IBMグループに入社し、IBM ITスペシャリストとしてシステム開発に従事。 2009年からベンチャー企業にて受託開発、コンテナ型無人データセンターの管理システム、ドローン開発などソフトウェアからハードウェア開発まで幅広く関わる。チーフテクノロジストとして2015年にモンスターラボへ入社し、2018年4月より最高技術責任者であるCTOに就任。 プロフィールはこちら
関連記事