
2022年11月に米国のOpenAI社が発表したChatGPTは、瞬く間に生成AIの代表的存在となりました。ビジネスパーソンであれば、直接業務に関わらなくても一度はChatGPTを使ってみた人は多いのではないでしょうか。これから益々、発展していく可能性が高いChatGPTを正しく理解するためには、その基盤となっている仕組みである「大規模言語モデル(LLM)」についても適切な知識を身に着ける必要があります。今回はその基本的な知識と活用事例、さらにChatGPT以外のモデルを紹介します。
➡︎【5分でわかる】ChatGPTの導入ポイントと活用事例 <資料ダウンロード>
目次
大規模言語モデル(LLM)とは
大規模言語モデル(LLM)について理解を深めるためには、まず言語モデルそのものの意味を把握する必要があります。言語モデルの定義と大規模言語モデルの仕組みについて解説します。
| ★まとめ ・大規模言語モデルは大量のデータを学習し、言語表現の確率予測の精度を高めた技術 ・文章やコミュニケーションが必要なビジネス分野でも活用される ・セキュリティや正確性の課題があり、学習方法や使い方などの改善が必要 |
言語モデルとは
言語モデルとは、自然言語処理に使われる技術の1つです。人間が日常的に使用する言語のパターンや言い回し、文法、意味を理解すると同時に、単語の次にどの単語が続くのかを予測することができます。
言語モデルを端的に言い表すと「言語表現の確率分布」のことです。例えば「人気の果物は?」という単語列に対して「①りんご:52%」、「②みかん:30%」、「③もも:12%」、「④スイカ5%」、「⑤レタス1%」といったような出現確率でモデル化することを指します。より自然な文章に対して高い確率を割り当て、野菜に分類されるスイカやレタスは低い確率にすることで、違和感の少ない文章の出力を実現しています。
一般的には、言語モデルは大量のテキストデータ(通常はインターネットから収集されたもの)を学習し、その情報をもとに新しい文を生成したり、与えられたテキストの文法的な正確さを評価したりします。
大規模言語モデル(LLM)の仕組み
大規模言語モデル(LLM)は、大量のテキストデータで学習した言語モデルを指します。特に「計算量」「データ量」「モデルパラメータ数」を巨大化させることで、より正確で自然なテキスト生成ができるようになりました。
LLMを学習させる際は、主に大量の学習データによる事前学習と微調整であるファインチューニングが繰り返し行われます。事前学習では大量のテキストデータを収集し、その単語やフレーズの出現パターンを学習します。一定の学習が終了した言語モデルに対しては、検証用データでテストを行いパラメータの微調整とモデルの妥当性を判断し、最適化を図るファインチューニングが行われます。
一般的にLLMが文章を出力するまでには、以下の流れを繰り返します。
1.トークン化:入力文章を最小単位の単語に分け、ベクター化する
2.文脈理解:入力文章について単語どうしの関連性を計算
3.エンコード:特徴量を抽出
4.デコード:次の単語(トークン)を予測
5.入力文章の次のトークンの確率を出力
➡︎【5分でわかる】ChatGPTの導入ポイントと活用事例 <資料ダウンロード>
大規模言語モデル(LLM)を活用できる分野
すでにLLMは、文章やテキストデータを扱うことの多いビジネス領域を中心に活用されており、具体的にはチャットボットや検索エンジンなどの分野が挙げられます。これらの具体的な活用例やメリットを中心に紹介します。
チャットボット
チャットボットは、カスタマーサポートや個別に最適化された情報提供など、さまざまなビジネスシーンで利用されています。
例えば、カスタマーサポートのチャットボットでは、顧客からの質問に対して適切な答えを提供する能力が求められます。ユーザーとの会話をより自然に、かつ効率的に進められるLLMはチャットボットと相性の良いシステムといえるでしょう。
さらに、LLMは言葉遣いや表現のニュアンスを理解する能力も持っているため、ユーザーの会話スタイルに適応した対話が可能です。LLMの精度向上によってチャットボットは、あたかも人間と話しているような対話体験ができるよう発展することが予想されます。
検索エンジン
GoogleやYahoo!に代表される検索エンジンもLLMが活用される分野です。これまでも検索欄に入力されたキーワードからユーザーの検索意図を正確に把握するためにLLMの技術は活用されていました。
例えば、「最新のIT技術のトレンド」という入力に対して、LLMは各単語の意味だけでなく単語の組み合わせによってどのような意味を持つのかを理解できるため、より正確な検索結果を表示することができるのです。また、ユーザーの自然な言葉遣いや専門用語に対しても理解する能力があるため、品質向上につながっています。
2023年には、MicrosoftがLLMの1つであるChatGPTの技術を自社の検索エンジンであるBingに組み込むことを発表し話題になりました。それに対し、Googleも独自の生成AIエンジンであるBardや、AIが生成した回答を検索結果のトップに表示する機能(SGE・Search Generative Experience)を発表するなど競争とサービス革新が進んでいる分野といえるでしょう。
テキスト生成
LLMの自然な文章を生成する能力は記事作成やSNSの投稿作成にも役立ちます。2023年現在、試験的にニュース記事やブログ投稿を自動生成することも行われており、大量の記事を短時間で作成する必要があるニュース会社やマーケティングチームにとって有益な技術といえるでしょう。
また、指示段階で特定のテーマやスタイルを指定することで、それに合わせた文章の生成が可能です。生成される文章の話題や視点、言葉遣いなども調整できるため、企業のメディアやSNSで読者に最適化した情報提供も可能になるでしょう。
そのほか、LLMは文章の要約や翻訳、文章の補完能力も優れており、ビジネスレポートの作成や学術的なリサーチなどの業務にも活用可能です。要約や翻訳は文脈の理解だけでなく、重要度の高い文章を認識しそれらを再構築して生成するプロセスが必要でしたが、LLMの学習能力と予測能力によって精度の向上を実現しています。
➡︎【5分でわかる】ChatGPTの導入ポイントと活用事例 <資料ダウンロード>
大規模言語モデル(LLM)の課題
幅広い分野で活用できる生成AIとして注目されるLLMのサービスですが、学習データのバイアスや正確性、セキュリティの問題など課題も挙がっています。今後、社会で広く活用されるにはこれらの課題への対処と改善が必要になるでしょう。
学習データのバイアス
LLMはその訓練データからパターンを学習し、それにもとづいて新しい予測を行います。そのため訓練データが持っているバイアスを反映してしまうという課題を持っています。
例えば、性別や民族、宗教に対する偏ったデータが訓練データに含まれている場合、LLMはそれらのバイアスを学習し、それにもとづく結果を出力する可能性があるでしょう。
対策としては、学習時にできるだけ幅広い属性(性別、年齢、人種、宗教など)のデータを収集する、公的な機関から入手したデータを中心に使う、人が精査したデータで学習させるなどの方法が挙げられます。
セキュリティ・プライバシーのリスク
LLMは学習と文章生成の過程で機密性の高い情報を扱う可能性があるため、セキュリティやプライバシー上のリスクも存在します。
例えば、カスタマーサポートの職場でユーザーからの入力情報を処理する場合、ユーザーのプライバシーを侵害する可能性があります。LLMに対して入力した機密情報がモデルの学習に使用され、未承認の第三者に漏洩する可能性があるためです。
これらの問題を解決するためには、データの取り扱いに関する厳格な規則を設けることが必要で、LLMを使用する側の対応も必要といえるでしょう。
★生成AIのセキュリティリスクについて詳しくはこちら

情報の正確性
LLMは学習データから単語間の統計的な確率分布をもとにテキストを生成しますが、その生成された情報が必ずしも正確であるとは限りません。「正確」か「不正確」かを判断する仕組みではないためです。偽の情報をあたかも本当であるかのように出力する現象は「ハルシネーション(幻覚)」と呼ばれています。
これらの問題を改善するためには、回答の誤りを提示することや適切な回答例の提示など、ユーザーがLLMの出力に対して適切なフィードバックを行う必要があるとされています。
日本語固有の難しさ
LLMは英語中心の学習データにもとづいて設計されることがほとんどで、日本語特有の言語的な複雑さに対応するのは難しいとされています。
これまでの言語モデルでも、自然言語の文章を構造化した学習用の大規模なデータが少なく、あったとしてもテキスト内にノイズが存在しており、その除去作業も必要でした。
学習データ以外にも、以下のような日本語固有の事情から、LLMが自然な会話に近い精度を出すためのハードルは高いといわれます。
・日本語は語順の自由度が高いこと
・1つの文章内に多種類の文字(ひらがな、カタカナ、漢字、ローマ字など)が存在すること
・同じ読み方で全く異なる意味の「同音異義語」の存在
・主語や目的語の省略が多く、省略された単語を推測する必要があること
これらの課題はありますが、最近ではOpenCALMやRinna-3.6Bなど、日本語に特化したLLMの開発も進んでいます。
➡︎【5分でわかる】ChatGPTの導入ポイントと活用事例 <資料ダウンロード>
大規模言語モデル(LLM)の種類一覧
LLMにはさまざまなモデルの種類が存在し、現在も世界中の企業や機関、開発者から発表され続けています。有名なGPTシリーズや日本語特化のLLMなど、5つのモデルについて以下で紹介します。
GPTシリーズ
GPT-4oおよびGPT-4o miniはOpenAIによって開発されたLLMであるGPTシリーズの最新モデルです。GPT-4の後続モデルとして開発されました。カバーする知識範囲は非常に広く、一般的な質問応答や文章生成、要約、翻訳といったテキストの入力、生成が可能です。また、画像や音声といった複数の形式のデータを処理でき、従来のモデルからさらに幅広い用途に対応することができます。
正確なパラメータ数は未公開のため不明ですが、GPT-4oはGPT-3.5の1,750億パラメータを大幅に超えるとされており、その結果、より正確な文脈理解と微妙なニュアンスの把握が可能となりました。
また、トレーニングデータにおいても最新データまで含むものとなっています。
★ChatGPTについて詳しくはこちら

Gemini
GeminiはGoogleによって発表された大規模言語モデル(LLM)で、PaLM2の後継モデルとされています。元々はBardという生成AI検索サービスに搭載されていたLLMですが、2024年にサービス名もGeminiへと変更されました。
他社のサービスと同様にマルチモーダル処理が可能ですが、特に特徴的なのは他のGoogleのサービスと直接的な連携が可能ということが挙げられます。つまりGoogleドキュメントやスプレッドシート上でGeminiにアクセスし、コンテンツの作成や情報の要約、データの管理、表の作成などが可能となっています。
Llama
LlamaはMetaが2023年に発表したLLaMAの後続モデルです。現在Llama 4までリリースされています。
モデルとしてはLlama 4 Scout、Llama 4 Maverick、Llama 4 Behemothの3モデルがあります。(2025年4月現在:Llama 4 Behemothは開発中)
オープンソースであるため、世界中の開発者がLlamaをベースにLLMを制作しており、商用利用可能なモデルも公開されています。
Claude
ClaudeはAnthropic社によって開発されたLLMで、現在はClaude 3.7 Sonnetが最新モデルとなります。
最大の特徴は、「ハイブリット推論モデル」と呼ばれる機能で、ユーザー側で標準モード(すばやい応答)と拡張思考モード(段階的な深い推論)を切り替えて使用できます。ただし拡張思考モードへの切り替え有無は有料版のみの提供となっています。
OpenCALM
OpenCALMは2023年にサイバーエージェントが一般公開した日本語LLMです。オープンな日本語データで学習されており、最大68億パラメータで日本語および日本文化に強いLLMという特徴があります。
また、商用利用可能なライセンスで提供されており、本モデルをベースにチューニングをすることで、チャットボットやRPAなどの対話型AIサービスの開発も可能になるでしょう。
➡︎【5分でわかる】ChatGPTの導入ポイントと活用事例 <資料ダウンロード>
大規模言語モデル(LLM)の活用事例
実際にLLMを活用している企業の事例を紹介します。
質問対応ボット
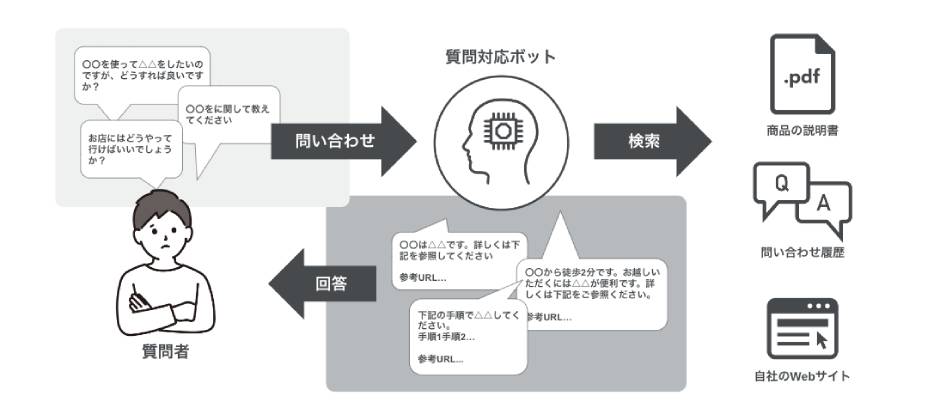
ボットに対して質問を入力すると、社内で過去に調べた情報や問い合わせ履歴などを検索し、概要をまとめて回答してくれます。LLMを活用することで、社内に散らばっているナレッジを活用したボットを作成することが可能です。
社内ナレッジを参照して回答するチャットボットとしての活用例を紹介します。
[入力内容]
高齢者見守りサービスにはどのような種類がありますか?箇条書きで、どのようなアプリかの概要も教えてください。
[出力内容]
高齢者見守りサービスには以下の種類があります。
・みてるちゃん:見守りボット
・ALSOK緊急通報サービス:緊急通報サービス
・お元気ですか:80種類のメッセージを簡単に作成・送信可能なアプリ
また、Slackのインターフェースを利用して、特定のメンションを付けて質問をすると社内のGoogleドライブ内に保存している情報を参照して回答する仕様のシステムにすることも可能です。
検索する対象が社内の情報であれば社内向けのチャットボットとして、お客様向けの情報であれば社外向けのお客様対応チャットボットとして活用できます。
データ整理
社内に散らばったデータを読み取り、要約やタグ付けをして構造化するデータ整理AIとして活用できます。
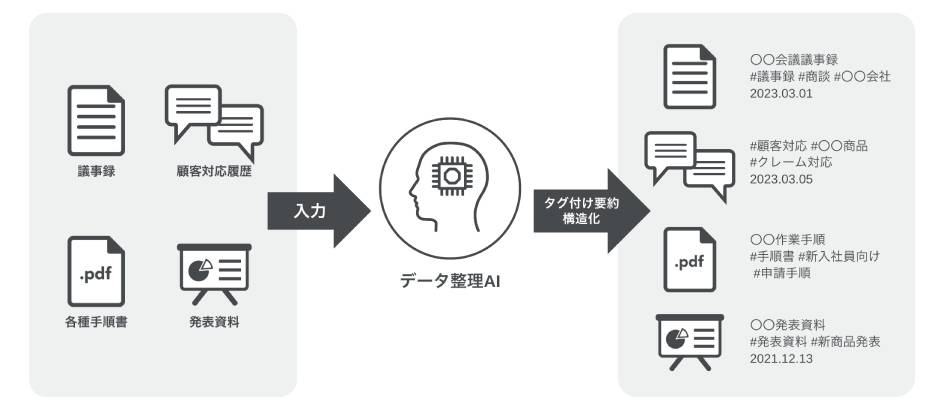
今まで議事録や顧客対応履歴などは、人しか意味を読み取ることができませんでした。しかし、LLMを使うことによってAIがデータを理解した上で構造化できるようになります。
たとえばブログ記事の内容をAIに渡すと、内容を読み込んでたくさんのタグを生成してくれます。人間が行う場合、文章を読んで理解して、まとめて、と非常に時間のかかる作業ですが、AIは素早く多くのタグを生成するため、大幅に業務を効率化できます。
マーケティング
マーケティング活動にもLLMを活用できます。
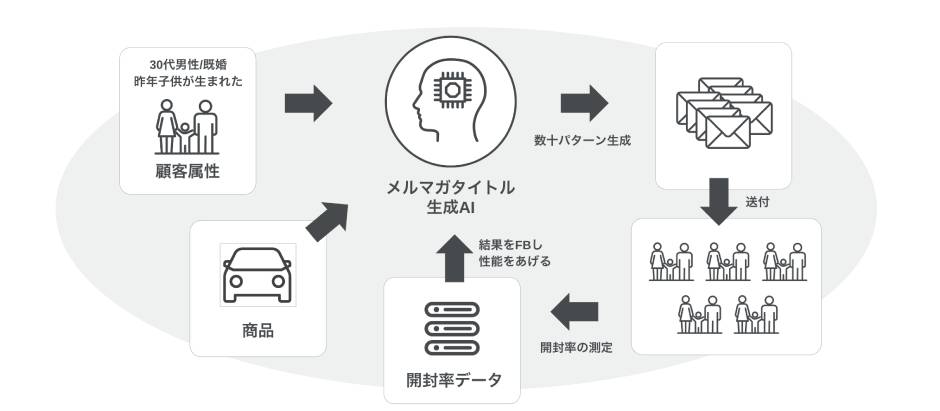
たとえば「特定の属性を持つターゲットに、このような商品を売り込みたい」と入力すると、メルマガタイトルを数10パターン生成してくれます。これにより今まで不可能だった粒度でのターゲッティングが可能です。
実際の入力例・出力例を紹介します。
[入力内容]
#顧客属性
・30代男性
・既婚
・昨年子どもが生まれた
#商品情報
・車体サイズ:全長4,000mm、全幅1,600mm、全高1,700mm
・エンジン:1.3L NR-MLL型直列4気筒MMNOエンジン(Pestroサイクル)
・定員:5名
・インテリア:スライド調整可能な後部座席、大型収納スペース、スマートエントリー&スタートシステム
・エクステリア:大きなヘッドライトとテールライト、大きな窓、高い屋根ライン ・・・など
[出力内容]
1.【30代男性必見】家族に優しい車を手に入れよう!
2. 既婚男性におすすめ!子どもも喜ぶ快適な車体サイズの新車
3.【子育て世代必見】安全機能充実のファミリーカーで安心ドライブ ・・・など
さらに、送付したメルマガの開封率を測定し、AIへフィードバックすることで性能を上げ、より開封率の高いメルマガタイトルを生成できるようになります。
➡︎【5分でわかる】ChatGPTの導入ポイントと活用事例 <資料ダウンロード>
まとめ:大規模言語モデルの活用は企業の使い方がポイント
大規模言語モデル(LLM)について、仕組みや種類、ビジネス分野での活用例を紹介しました。
現在はChatGPTが有名ですが、今後はGoogleやMetaなどもLLMをもとにサービスを展開することが予想され 、競争も激しくなるでしょう。
LLMを活用する際は、「どのモデルをどのように活用するか」という使い方が重要になります。誤ったデータを公開したり、個人情報を流出させたり、使ううえでのリスクも含んでいるため、LLMの特徴を踏まえてルールを設けるなど企業の経営者は管理の徹底が大切です。
➡︎【5分でわかる】ChatGPTの導入ポイントと活用事例 <資料ダウンロード>
LLMの活用を検討している企業ご担当者様へ
モンスターラボは、LLMをさまざまな業務・プロダクトへ活かすためのサポートをいたします。2200件以上のサービス・プロダクト開発の実績から得られたデジタル領域の知見を活かし、ChatGPTをはじめとしたLLMを活用した企業独自のシステム構築を支援することが可能です。
モンスターラボでは日頃抱えるお悩みのご相談やお見積もりのご依頼を随時受付しております。「LLMで何ができるのか」「どのように業務に組み込むべきか」「セキュリティ面で懸念がある」など、検討段階の方もまずはお気軽に下記のボタンからお問い合わせください。
直近のイベント



記事の作成者・監修者

平田 大祐(株式会社モンスターラボ 常務執行役員)
2004年IBMグループに入社し、IBM ITスペシャリストとしてシステム開発に従事。 2009年からベンチャー企業にて受託開発、コンテナ型無人データセンターの管理システム、ドローン開発などソフトウェアからハードウェア開発まで幅広く関わる。チーフテクノロジストとして2015年にモンスターラボへ入社し、2018年4月より最高技術責任者であるCTOに就任。 プロフィールはこちら
関連記事













