Der Einstieg in maschinelle Lernmodelle kann überwältigend erscheinen, wenn die Daten unvollständig sind, der Return of Investment sofort erwartet wird und die Geschäftsethik nicht berücksichtigt wird. Erste Experimente und eine langfristige Strategie können jedoch einen enormen Wettbewerbsvorteil schaffen und bei der Umwandlung von Daten in Lösungen helfen.
In diesem Artikel werden Sie lernen:
- Warum langfristiger Erfolg mit maschinellem Lernen frühes und fokussiertes Experimentieren erfordert, das schnell scheitert.
- Wie neue Technologien bessere Daten für die Entscheidungsfindung liefern.
- Die Grundlagen des maschinellen Lernens und wie es sich von aktuellen Versicherungsberechnungsmodellen unterscheidet.
- Wie Sie loslegen und den versteckten Wert in Daten nutzen können.
Hier ist ein Beispiel, um meinen Standpunkt zu verdeutlichen:
Laut einem Bericht von Teradata investieren 80% der Unternehmen in maschinelles Lernen oder verschiedene Zweige von KI, um das Kundenerlebnis zu verbessern, Kosten zu minimieren oder Risiken zu managen. Für Versicherungsunternehmen gibt es zwei grundlegende Treiber, die zur Einführung neuer Technologien beitragen:

Die Implementierung neuer Technologien ist nur der erste Schritt, um die Vorteile der Digitalisierung voll auszuschöpfen. Oft ist die Anwendung von maschinellem Lernen mit einem Anstieg der Kosten, einem scheinbaren Mangel an Ergebnissen und viel Frustration verbunden. Von Anfang an die richtigen Erwartungen zu setzen, ist entscheidend für den späteren Erfolg.
Maschinelles Lernen in der Versicherung: langfristiger Erfolg erfordert frühes Experimentieren
In den meisten Fällen bringt die Einführung von maschinellem Lernen keine sofortigen Gewinne. Tatsächlich ist die frühe Implementierung von maschinellem Lernen mit einem Anstieg der Kosten verbunden und erfordert eine langfristige Strategie, um diese in Gewinne umzuwandeln. Das liegt an den Anforderungen an die Datenqualität und an der experimentellen Art der Technologie.
“Laut einer BCG-Analyse sehen mehr als die Hälfte der Unternehmen, die in maschinelles Lernen investieren, keinen Return to Investment.”
– Tobias Lund-Eskerod, Delivery Director, Monstarlab
“Wenn die Daten nicht repräsentativ sind, werden die Modelle falsch sein. In der Anfangsphase werden sich oft unvollständige Datensätze finden, die entweder vervollständigt werden müssen oder das Problem muss sich ändern”, sagt Tobias Lund-Eskerod, Delivery Director bei Monstarlab, und weiter:
“Bei der Anwendung der Technologie werden sehr wahrscheinlich unvorhergesehene Erkenntnisse auftreten. Diese Erkenntnisse können einen großen Einfluss auf das Budget für das Projekt haben, was es schwierig macht, alle von dem Potenzial zu überzeugen”. Aber die Frage nach den finanziellen Kosten des maschinellen Lernens scheint bei IT-Entscheidenden ebenso wichtig zu sein wie der potenzielle Gewinn. Laut Teradata erwarten Unternehmen, die maschinelle Lerntechnologie eingeführt haben, in Zukunft einen erheblichen ROI:
Erwarteter ROI für jeden in KI-Technologien investierten Dollar
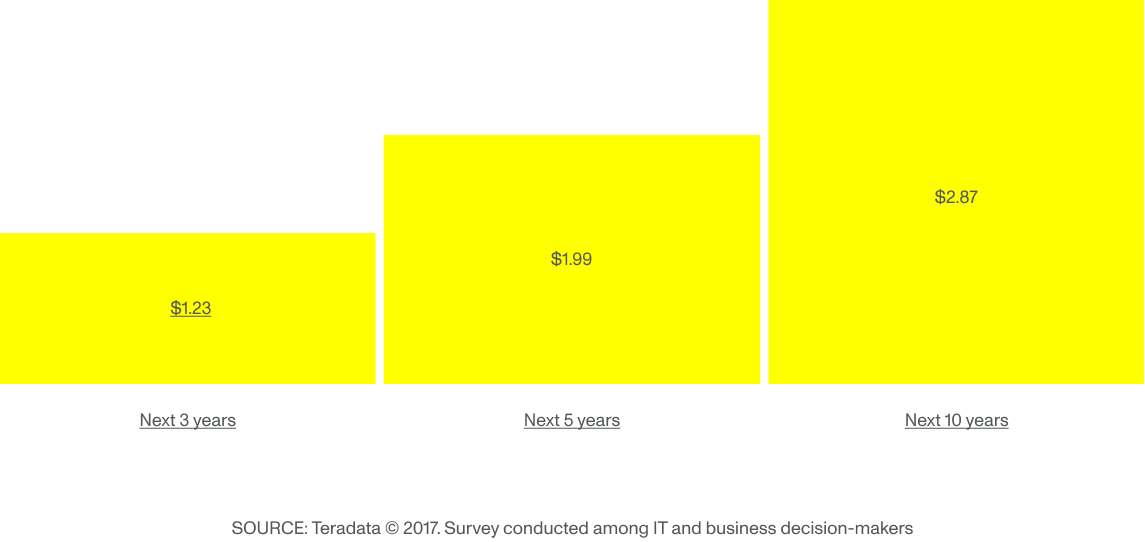
Da Führungskräfte eine Verdreifachung des ROI innerhalb von zehn Jahren erwarten, ist eine langfristige Strategie mit kontinuierlichen Investitionen, mehrfachen Tests und Evaluierungen unumgänglich. Dennoch fällt es Führungskräften schwer, sich voll auf die Technologie einzulassen, da das Geschäftsmodell der Versicherungsbranche mit hohen Margen und jahrzehntelanger Stabilität erfolgreich ist. Die Entmystifizierung von ML ist entscheidend für eine größere und frühere Akzeptanz.
Entscheidungstragende durch neue Informationen stärken
Das Training von Vorhersagemodellen, um manuelle Aufgaben zu verarbeiten und Muster in strukturierten, halbstrukturierten und umstrukturierten Datensätzen zu finden, um bessere Geschäftsentscheidungen zu treffen, ist für alle Versicherungsunternehmen reizvoll. Aber die Realität ist, dass einige, obwohl sie sehr viele Kundendaten haben, vorsichtig sind, was die Anwendung von maschinellen Lerntechnologien bewirken könnte.
“Der Kern einer Versicherungsgesellschaft besteht darin, Risiken auf der Grundlage persönlicher Informationen zu bewerten und passende Policen zu erstellen. Und da wir alle Individuen sind, birgt maschinelles Lernen das Potenzial, uns alle unterschiedlich zu behandeln, was zu Diskriminierung führen kann”, sagt Tobias Lund-Eskerod.
Ein wichtiger Bestandteil jeder Versicherungsgesellschaft ist es, ihren gesamten Kundenstamm in kleinere Gruppen zu unterteilen. Aber maschinelles Lernen birgt das Potenzial, Gruppen auf sehr kleine Gruppen herunter zu brechen und Einzelpersonen auf der Grundlage unangemessener Kriterien wie Rasse, Geschlecht, sexuelle Orientierung usw. zu bewerten.
“Aber selbst mit diesem integralen Risiko des maschinellen Lernens basiert die Technologie immer noch auf Daten und mathematischen Methoden”, sagt Tobias Lund-Eskerod. Daten, die Versichernde auswählen, bereinigen und aufbereiten sowie mathematische Methoden wie Regression, Klassifizierung und Clustering. Wie die Versichernde entscheiden, die Ergebnisse zu interpretieren, liegt bei den Geschäftsführenden. Die Technologie an sich ist nicht in der Lage, Unterscheidungen zu treffen, Fragen zu stellen oder Probleme zu lösen. Sie hat jedoch das Potenzial, Kosten zu minimieren, Gewinne zu steigern und vor allem eine präzisere Kunden-Lebenswert-Berechnung mit minimaler menschlicher Intervention und Anleitung durchzuführen.
Maschinelles Lernen nutzen, um den Kunden-Lebenswert zu verbessern – Beispiel
Maschinelles Lernen ist nur so gut wie die vorliegenden Daten. Da Versicherungsunternehmen laut einer Accenture-Umfrage jedoch nur 10-15% ihrer Kundendaten verarbeiten, gelingt es den Versichernden nicht, ihre Erkenntnisse zu nutzen, um präzise KLWs für ihre Kunden zu berechnen. Einblicke, die sowohl für die Versichernden als auch für die Versicherten wertvoll sein könnten.
Eine gängige Praxis für Versichernde ist die Verwendung von Alter, Wohnort und externen soziodemografischen Parametern als Input für die Preisgestaltung und KLW-Bestimmung. Diese Parameter werden häufig in einem GLM- oder multiplen linearen Regressionsmodell verwendet, bei dem jeder Eingabe ein Faktor zugeordnet wird, der sich auf den KLW auswirkt. Beispielsweise entspricht eine junge Kundin in einer ruhigen Nachbarschaft einem höheren erwarteten CLV als eine junge Kundin in einer Nachbarschaft, die statistisch gesehen anfällig für Diebstähle ist.
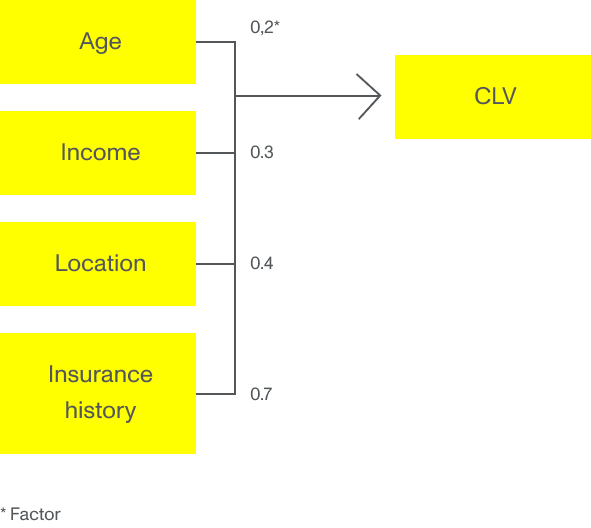
Aber stellen Sie sich vor, wenn die Korrelation anders wäre. Stellen Sie sich vor, dass die junge Kundin, die in der Nachbarschaft wohnt, die statistisch gesehen anfällig für Diebstähle ist, mit geringerer Wahrscheinlichkeit einen Versicherungsantrag ausfüllt, als das multiple lineare Regressionsmodell vermuten lässt. Wenn wir Algorithmen für maschinelles Lernen auf dieses Beispiel anwenden, füttern wir den Algorithmus mit Unmengen historischer Daten über Kund:innen, die im Laufe der Zeit von der Versicherungsgesellschaft, statistischen Datenbanken und staatlichen Organisationen gesammelt wurden. Mit diesen Daten können maschinelle Lernmodelle Muster erkennen und die Parameter entdecken, die für die Berechnung eines präziseren KLW wirklich wichtig sind. Der wichtigste Parameter für die junge Kundin in der Problemgegend ist vielleicht nicht der Standort, sondern die Ausbildung, der Familienstand oder die Anzahl der Versicherungspolicen – oder alles zusammen.
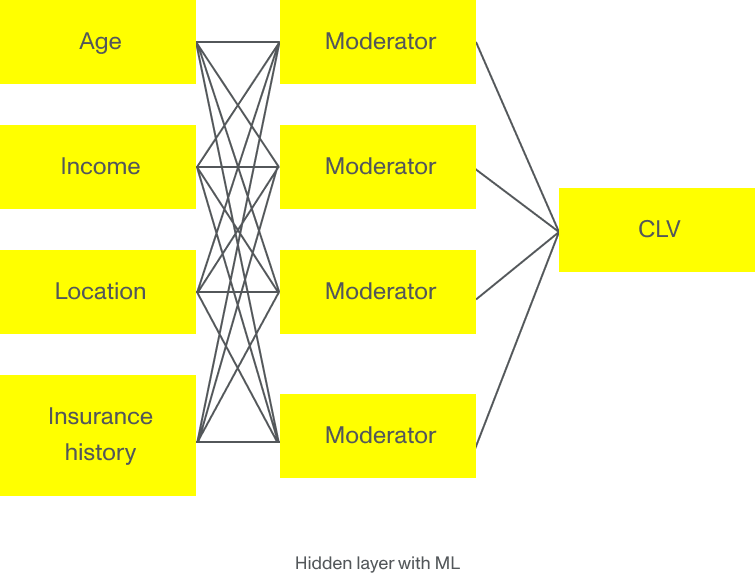
Die Komplexität und die Menge an Informationen ist für multiple Regressionsmodelle zu groß, um sie abzudecken. Hier zeigen neue Technologien wie maschinelles Lernen und Deep Learning ihr wahres Können, indem sie eine genauere Bewertung und Prognose für Kund:innen ermöglichen.
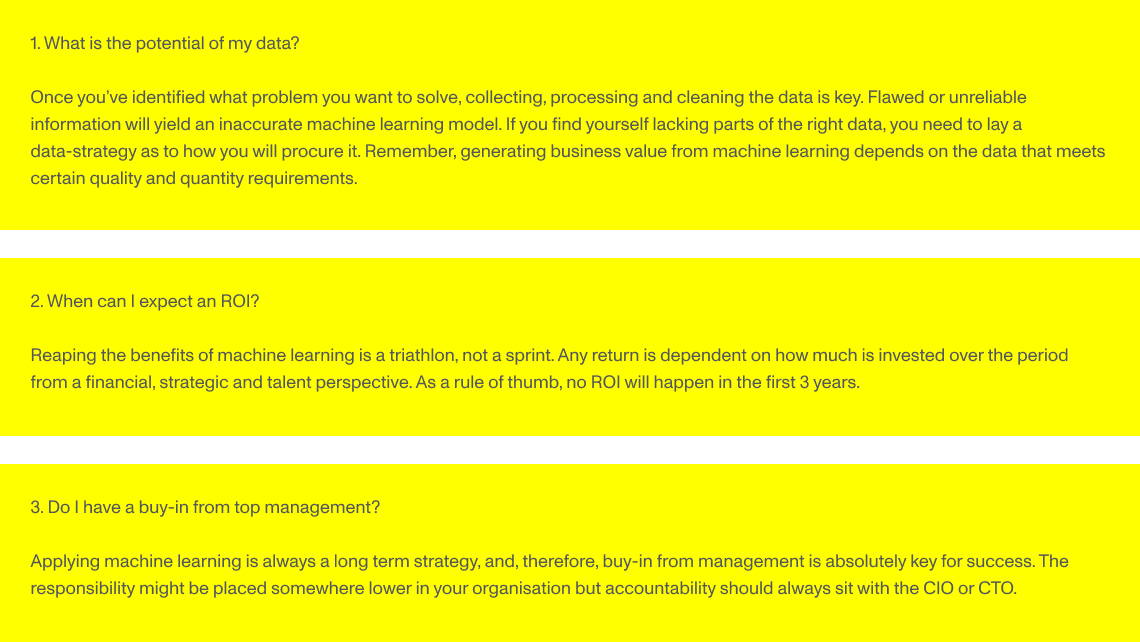
Mit maschinellem Lernen anfangen
Obwohl Versicherungsunternehmen seit vielen Jahrzehnten profitable Margen und ein nachhaltiges Geschäftsmodell haben, ist die Mehrheit der Führungskräfte der Meinung, dass sie neue Technologien einbeziehen müssen, um für Kund:innen interessant zu bleiben.
“Laut einer Studie aus dem Jahr 2018 glauben 82% der Führungskräfte in der Versicherungsbranche, dass sie innovativ sein müssen, um einen Wettbewerbsvorteil zu erhalten. Doch 77% von ihnen fügen hinzu, dass die Technologie schneller voranschreitet, als sich ihr Unternehmen anpassen kann”, sagt Tobias Lund-Eskerod.
Mit anderen Worten: Es ist wichtig, sich jetzt mit maschinellem Lernen vertraut zu machen, um in der sich ständig verändernden digitalen Landschaft relevant zu bleiben. Aber der Einstieg kann sich wie die Suche nach einer Nadel im Heuhaufen anfühlen. Um die Räder ins Rollen zu bringen, sollten Entscheidungsträger:innen in Versicherungsunternehmen die Reise zum maschinellen Lernen mit der Beantwortung dieser drei Fragen beginnen: