By Alex Holdsworth, Executive Director, Monstarlab
What does it mean and why does it matter?
We know that the ever-increasing quantities of data are fueling a new era of fact-based innovation in corporations, backing up new ideas with solid evidence. For the past decade, organisations have doubled down on investment in exploiting, but for becoming ‘data-driven’ remains an elusive goal.
What does it mean and why does it matter?
Firstly, why should we care? Because we know that by using a data-driven approach, you eliminate many of the human biases and heuristics in decision making. Furthermore, when embedding this insight using automation and artificial intelligence means a lot less time spent on getting to the action. In plain English? You make decisions faster and better – and realise value from the top and bottom line.
- Netflix – so good at targeted content promotion that an estimated 80 percent of content streamed on its platform is influenced by its recommendation system.
- Ocado – owns their customer data (and over 50,000 SKU performance) which meant they can switch suppliers (Waitrose to Marks & Spencer) with minimal loss of service or customer attrition
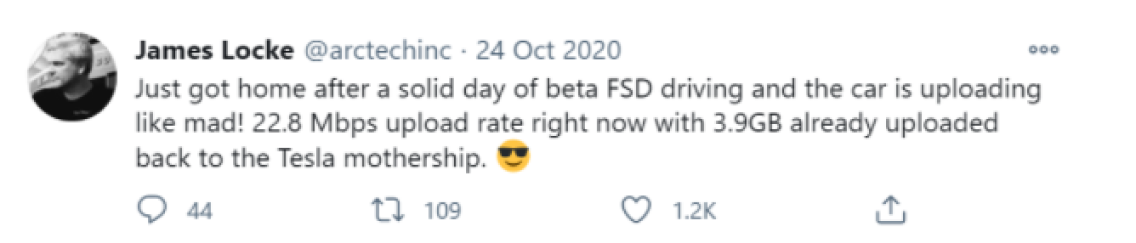
- Tesla’s Fleet Learning software gathers sensor data from over 1m of its vehicles, which it is now turning into a gigantic training set for self-driving technology
So, why is it so hard?
Our work in a range of industries indicates that the biggest obstacles to creating data-driven organisations aren’t technical; they’re cultural. It is simple enough to describe how to inject data into ad hoc decisions, but very hard to make this the norm.
- You need a lot of data – both breadth (customer, transaction, master) and depth (often multi-year time series). Having a large data set means then you can watch out for outliers and deviations from the average that are often an opportunity – or a cause for concern.
- It takes time which not everyone has. For startups and larger organisations, it can be challenging to be entirely data-driven due to internal resources and capabilities.
So we’ve distilled a five-point cheat sheet to help shortcut and overcome these two barriers
A pragmatist guide to getting going
A. Find your competitive advantage. Most organisations will not use data to the scale of a technology giant like Netflix, Ocado and Tesla (trillions of new daily events generating hundreds of terabytes of data) – and they don’t need to. In our experience, many organisations struggle to grasp this trade-off: how does the data gathered and analysed contribute to realising the business objectives. Creating data capabilities should be treated with the same rigour as any other infrastructure investment decision – it is an expensive decision to get wrong. The cost alone of data storage; licenses; maintenance will likely run into the millions of dollars for most large organisations.
B. Choose the metrics that drive value – and focus on them. Maintaining focus on what matters to the business is crucial. At the enterprise level often, proxy KPIs are a stand-in for your high-level organisation objectives – indeed you may already have them as part of a corporate scorecard. In product management, you can assess the metric in an A/B test, to answer the question, “should we launch this feature, or not?”.
At Monstarlab we use Value Trees to outline how data and analytics metrics are tied back to business value.
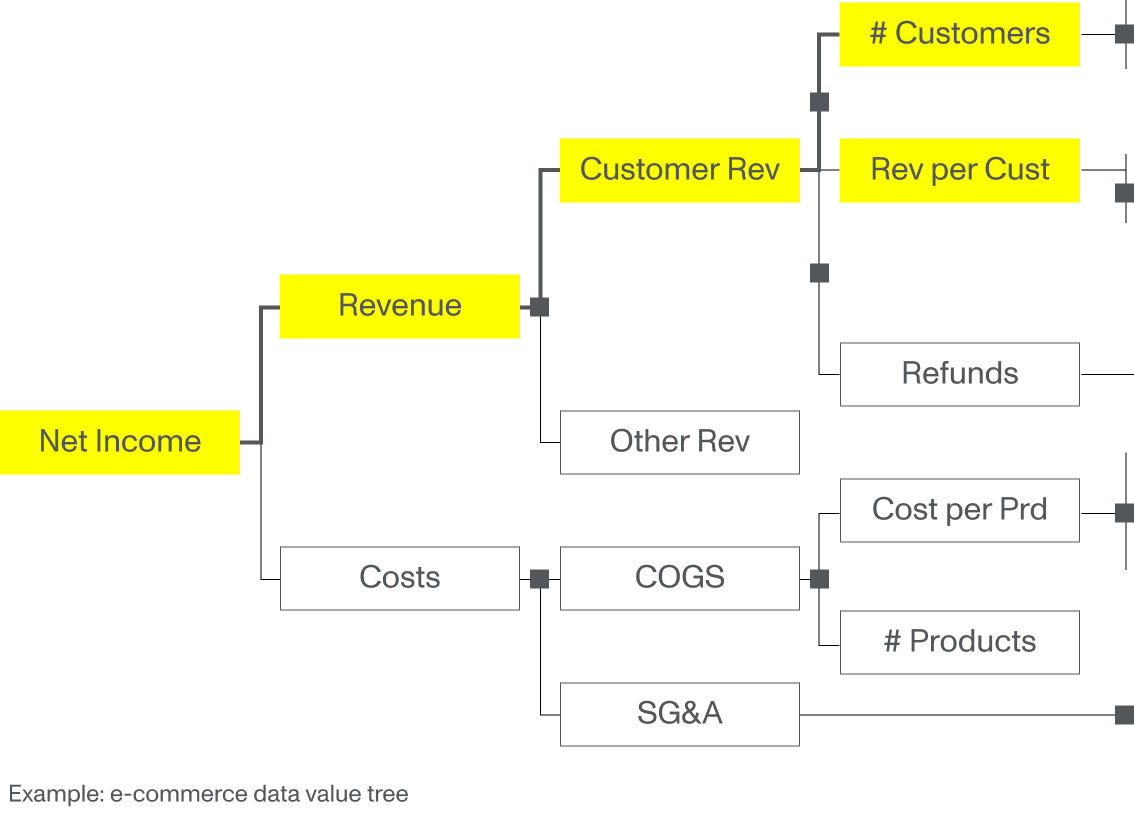 Example: e-commerce data value tree
Example: e-commerce data value tree
C. Encourage being comfortable with uncertainty. Many leaders continue to ask their teams for answers without a corresponding measure of confidence. They’re missing a trick. Requiring teams to be explicit and quantitative about their levels of uncertainty has three, powerful effects.
Finally, an emphasis on understanding uncertainty pushes organizations to run experiments. “At most places, ‘test and learn’ really means ‘tinker and hope,’” a retailer’s chief merchant once noted. At his firm, a team of quantitative analysts paired up with category managers to conduct statistically rigorous, controlled trials of their ideas before making widespread changes.
D. Focus on recruiting data engineers, not always data scientists. The realities of getting insight from data are not pretty: 80% of an AI project has to do with data preparation activities. Many organisations make the mistake of building a capability with the ‘pointy end’ of data, who often sit redundant without the petrol (clean data) to power their model engines.
E. Get a controlled dataset in the hands of users and then fix issues quickly. Many of our clients use a simple strategy to break the cycle of slow development. Instead of bureaucratic ‘information governance’ programmes to reorganise data, or similarly the pandora’s box of unconstrained data democracy, they drip-feed access to just a few key datasets to all users. As they go, they then fix the plumbing where it is in the critical path and ensure the fix aligns with the target architecture. All important data standards and lineage (the blueprint for where data comes from and how it is managed) is then iteratively developed over time – but be warned, this is a continuous process.
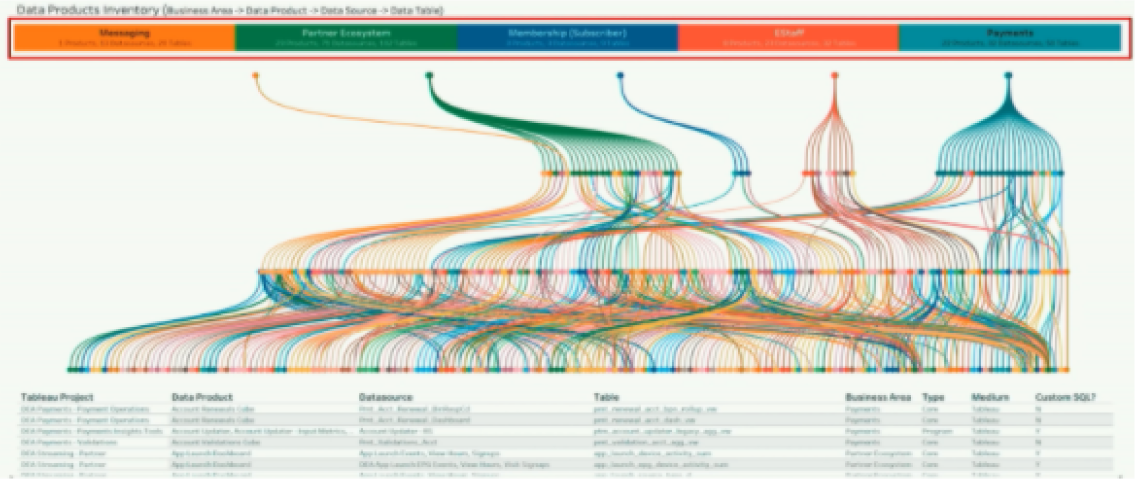 Example: Netflix Enterprise Data Lineage Map, 2018
Example: Netflix Enterprise Data Lineage Map, 2018