Verzekeringsmaatschappijen zien langzaamaan de waarde en potentiële impact van machine learning (ML) in bij het maken van goede en lonende polis keuzes voor elk individu. Aan de slag gaan met ML-modellen kan echter voor elke verzekeringsmaatschappij een overweldigende taak lijken. Dit is vooral het geval als de gegevens onvolledig zijn, het rendement van de investering onmiddellijk wordt verwacht en bedrijfsethiek onbesproken blijft. Vroege experimenten en een langetermijnstrategie kunnen echter helpen om een concurrentievoordeel op te bouwen en besluitvormers binnen de sector helpen om gegevens om te zetten in bedrijfskritische oplossingen – zoals het omvatten van Customer Life Value (CLV)-berekeningen en beter gepersonaliseerde, niet-discriminerende polissen.
In dit artikel lees je meer over:
- Hoe nieuwe technologie betere data levert voor besluitvorming en accurate verdeling.
- De basis van machine learning en hoe het verschilt van de huidige berekeningsmodellen voor het verzekeringswezen.
- Waarom succes op de lange termijn met machine learning vroege en gerichte experimentatie vereist die snel faalt.
- Hoe je begint met het oogsten van de verborgen waarde in je data.
Het klantenaanbod versterken door nieuwe informatie te onthullen
Het trainen van voorspellende modellen om handmatige taken te verwerken en patronen te vinden in gestructureerde, semi-gestructureerde en ongestructureerde datasets om betere beslissingen te nemen zijn aantrekkelijk voor alle verzekeringsmaatschappijen. Maar de realiteit is dat ondanks het feit dat ze grote hoeveelheden klantgegevens hebben, sommige bezorgd zijn over de potentiële gevolgen van het toepassen van machine learning-technologie.
“De kern van elke verzekeringsmaatschappij is het inschatten van risico’s op basis van persoonsgegevens en daar passende polissen voor te creëren. En aangezien we allemaal individuen zijn, biedt machine learning de mogelijkheid om ons allemaal afzonderlijk te behandelen, wat kan leiden tot discriminatie,” legt Tobias Lund-Eskerod uit.
Een belangrijk onderdeel van elke verzekeringsmaatschappijen is het onderverdelen van hun klantenbestand in kleinere groepen. Maar machine learning kan grotere groepen onderverdelen in zeer kleine en zo individuen gaan beoordelen op basis van ongepaste criteria zoals ras, gender, seksuele voorkeur, etc.
Maar zelfs met dit inherente risico van machine learning, blijft de technologie gebaseerd op data en wiskundige methodologieën, zegt Tobias Lund-Eskerod. Data die de verzekeraars selecteren, opschonen en voorbereiden, maar ook wiskundige methodologieën zoals regressie, classificatie en clusteren. Hoe verzekeraars beslissen het resultaat te interpreteren is volledig aan de bedrijfsleiding. De technologie zelf is niet in staat om te discrimineren, vragen te stellen of problemen op te lossen. Het heeft echter wel de potentie om kosten te minimaliseren, winsten te vergroten en vooral om een preciezere Customer Life Value te berekenen met minimale menselijke inmenging en sturing.
Machine learning om de Customer Life Value te verbeteren – voorbeeld
Machine learning is slechts zo goed als de data die het gepresenteerd krijgt. Maar gezien het feit dat verzekeringsmaatschappijen slechts 10-15 % van hun klantinformatie verwerken, aldus een enquête van Accenture survey, schieten ze te kort in het inzetten van hun inzichten om precieze CLV’s te berekenen voor hun klanten. Inzichten die tot waardevol beleid zouden kunnen leiden voor zowel de verzekeraars als de verzekerden.
Een vaak gebruikte methode voor verzekeraars is om leeftijd, woonplaats en externe sociaaldemografische parameters te gebruiken voor het vaststellen van de prijs en de CLV. Deze parameters worden vaak gebruikt in een General Linear Model (GLM) of een meervoudige lineaire regressiemodel waarin elke invoer een factor krijgt die de CLV beïnvloedt. Voorbeeld: een jonge klant woonachtig in een rustige buurt betekent een hogere verwachte CLV dan een jonge klant in een buurt waar statistisch gezien veel wordt ingebroken.
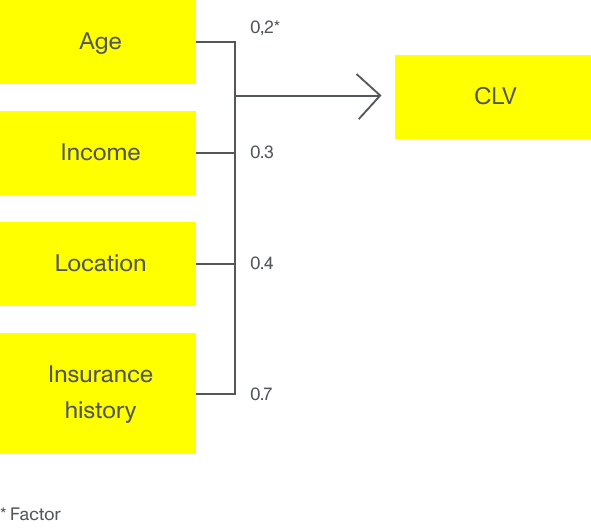
Maar stel dat die correlatie anders was. Stel dat de jonge klant die in de buurt woont met veel inbraken minder geneigd is een claim in te dienen dan het meervoudige lineaire regressiemodel aangeeft. Als we machine learning-algoritmes toepassen op dit voorbeeld, voeden we het algoritme met grote hoeveelheden gegevens uit het verleden die door de jaren heen door de verzekeringsmaatschappij over klanten zijn verzameld en uit statistische en overheidsdatabases komt. Wanneer machine learning-modellen al deze data hebben, kunnen ze de onderliggende patronen identificeren en de parameters bepalen die echt relevant zijn voor het berekenen van een preciezere CLV. De belangrijkste parameter voor de jonge klant in de slechtere buurt is mogelijk niet de locatie, maar het opleidingsniveau, burgerlijke staat of het aantal verzekeringspolissen, of zelfs een combinatie daarvan.
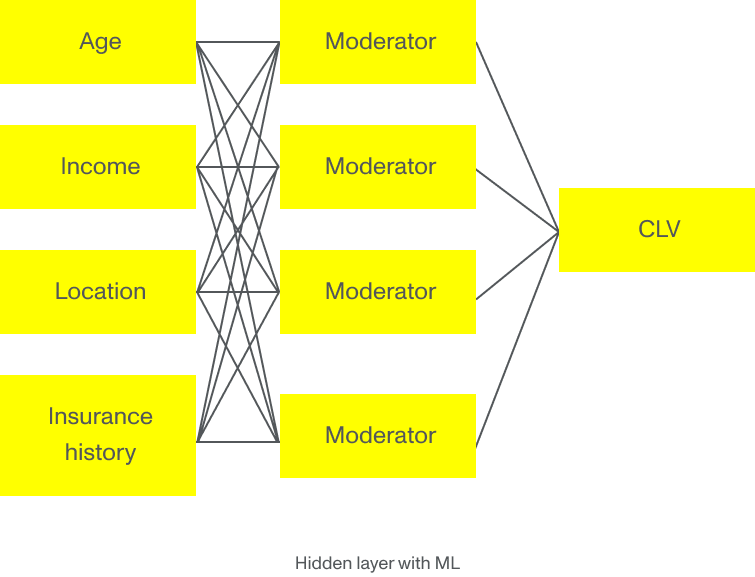
De complexiteit en het enorme volume aan informatie die beschikbaar is, is simpelweg te veel voor zelfs meervoudige regressiemodellen. Dit is waar nieuwe technologieën zoals machine learning en deep learning in uitblinken. Ze creëren een meer nauwkeurige waardering en voorspelling van de klanten.
Het stellen van verwachtingen:
Volgens een rapport van Teradata zijn de redenen van 80% van de bedrijven die hebben geïnvesteerd in machine learning of verschillende vormen van AI het verbeteren van de klantervaring, het minimaliseren van kosten of het beheersen van risico. Voor verzekeringsbedrijven dragen twee basale drijfveren bij aan de omarming van nieuwe technologie:


Het implementeren van nieuwe technologie is slechts de eerste stap in het volledig profiteren van de voordelen die digitaal te bieden heeft. Vaak gaat het toepassen van methodologieën voor machine learning gepaard met oplopende kosten een schijnbaar gebrek aan resultaten en een hoop frustratie. De juiste verwachtingen kweken vanaf het begin is essentieel voor later succes.
Succes op de lange termijn vereist vroeg experimenteren met machine learning
In de meeste gevallen zal het toepassen van machine learning niet meteen rendement opleveren. Sterker nog, de implementatie van machine learning wordt geassocieerd met hogere kosten en vereist een langetermijnstrategie om dat om te zetten in winst. Dit komt door de vereiste datakwaliteit en de exploratieve aard van deze technologie.
“Volgens een BCG analysis krijgt meer dan de helft van de bedrijven die geld steken in machine learning geen rendement op hun investering.”
– Tobias Lund-Eskerod, Delivery Director, Monstarlab
“Als de data niet representatief is, kloppen je modellen niet. In de beginfase heb je vaak te maken met onvolledige datasets. Deze moeten eerst volledig worden, of je moet het probleem dat je probeert op te lossen aanpassen,” vertelt Tobias Lund-Eskerod. Hij vervolgt:
“Wanneer je de technologie toepast, is de kans groot dat er onverwachte bevindingen de kop op steken. Deze bevindingen kunnen grote gevolgen hebben voor het budget dat ter beschikking is gesteld voor het project, wat het moeilijk kan maken iedereen ervan te overtuigen dat het potentie heeft.” Maar het omgaan met de financiële kosten van machine learning lijkt net zo belangrijk te zijn als de potentiële winst wanneer je het aan IT-besluitvormers vraagt. Volgens Teradata verwachten bedrijven die al aan de slag zijn gegaan met machine learning een aanzienlijke ROI in de toekomst:
Verwacht ROI voor elke geïnvesteerde dollar in AI-technologie
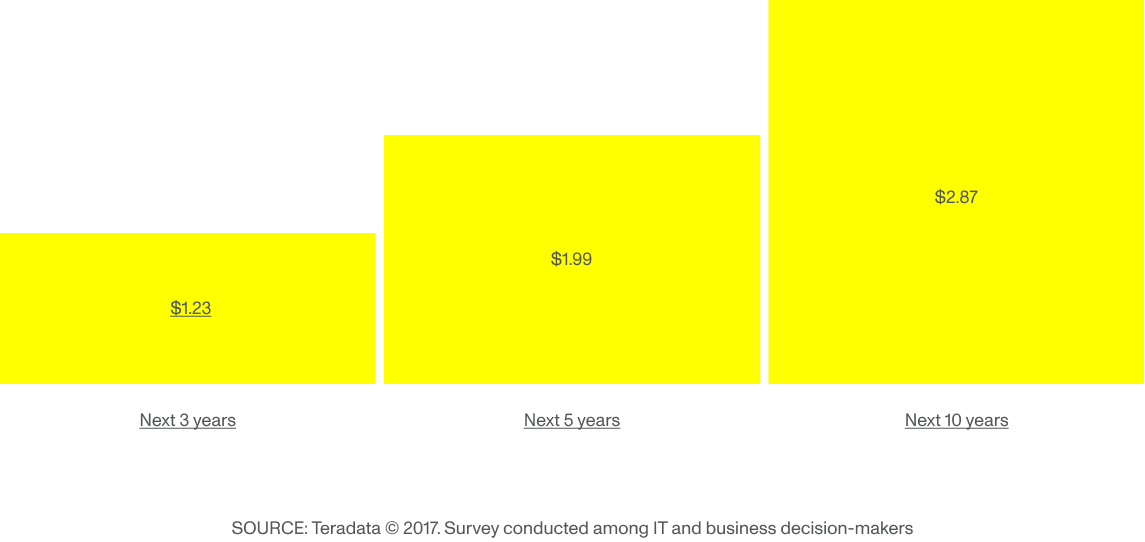
Gezien het feit dat directieleden verwachten dat de ROI zal verdrievoudigen binnen tien jaar, is het belangrijk om een langetermijnstrategie te hebben met doorlopende investeringen, meerdere tests en evaluaties. Toch hebben leiders in het bedrijfsleven moeite met vol gaan voor deze technologie omdat het bedrijfsmodel met hoge marges en stabiliteit al decennia succesvol is in de verzekeringsbranche. ML minder mysterieus maken, is cruciaal voor snellere en bredere acceptatie.
Hoe je aan de slag gaat met machine learning
Ondanks dat verzekeringsmaatschappijen al decennia prima marges en een duurzaam bedrijfsmodel hebben gekend, denken veel managers dat ze gebruik zullen moeten maken van nieuwe technologieën om relevant te blijven voor hun klanten.
“Volgens een onderzoek uit 2018 denkt 82% van managers in de verzekeringssector dat ze innovatief moeten zijn om de concurrentie voor te blijven. Toch geeft ook 77% van hen aan dat de technologie zich sneller ontwikkelt dan het bedrijf kan bijbenen”, zegt Tobias Lund-Eskerod.
Met andere woorden: nu bekend raken met machine learning is belangrijk om relevant te blijven in het veranderende digitale landschap. Maar het begin kan aanvoelen als zoeken naar een naald in een hooiberg. Om de dingen in beweging te brengen, zouden de besluitvormers van verzekeringsmaatschappijen aan hun machine learning-reis moeten beginnen door de volgende drie vragen te beantwoorden:







